Entstehung des Standardfehlers: Unterschied zwischen den Versionen
Wehner (Diskussion | Beiträge) Keine Bearbeitungszusammenfassung |
Nadia1 (Diskussion | Beiträge) KKeine Bearbeitungszusammenfassung |
||
| (8 dazwischenliegende Versionen von 3 Benutzern werden nicht angezeigt) | |||
| Zeile 1: | Zeile 1: | ||
{{Nav|Navigation| | {{Nav|Navigation|Statistik_Grundbegriffe|Hauptseite}} | ||
Der Standardfehler ist eine sehr wichtige statistische Kenngröße, die die Grundlage vieler statistischer Tests darstellt, zum Beispiel in regressionsanalytischen Verfahren. In diesem Text und in der App wird exemplarisch auf den Standardfehler des Mittelwertes eingegangen. | Der Standardfehler ist eine sehr wichtige statistische Kenngröße, die die Grundlage vieler statistischer Tests darstellt, zum Beispiel in regressionsanalytischen Verfahren. In diesem Text und in der App wird exemplarisch auf den Standardfehler des Mittelwertes eingegangen. | ||
Der Standardfehler des Mittelwertes ist ein statistisches Maß für die Genauigkeit der Schätzung des Populationsmittelwertes. Er entspricht der Standardabweichung der Verteilungen der Punktschätzungen des Populationsmittelwertes von Stichproben des Umfangs n einer Population. | Der Standardfehler des Mittelwertes ist ein statistisches Maß für die Genauigkeit der Schätzung des Populationsmittelwertes. Er entspricht der Standardabweichung der Verteilungen der Punktschätzungen des Populationsmittelwertes von Stichproben des Umfangs n einer Population. | ||
Der Standardfehler ist von der Standardabweichung in der Population und der Stichprobengröße abhängig und lässt sich | Der Standardfehler ist von der Standardabweichung in der Population und der Stichprobengröße abhängig und lässt sich mithilfe der folgenden Formel berechnen: | ||
[[File:1_2_Standardfehler_Formel.PNG|70px|link=Ausgelagerte_Formeln#Standardfehler|Ausgelagerte Formel Standardfehler]] | |||
Ist die Streuung der Stichprobenmittelwerte um den Populationsmittelwert gering, kann der Populationsmittelwert genauer aus dem Mittelwert einer einzelnen Stichprobe geschätzt werden. Bei größerer Standardabweichung σ in der Population steigt demnach der Standardfehler an, wohingegen er bei größeren Stichprobenumfängen n geringer wird. Weil in der Praxis weder der Standardfehler des arithmetischen Mittelwertes noch die Standardabweichung aus der Population bekannt ist, wird der Standardfehler des Stichprobenmittelwertes s<sub>X̅</sub> als Schätzwert für σ<sub>X̅</sub> verwendet. s<sub>X̅</sub> wird dabei mithilfe der Standardabweichung s und dem Stichprobenumfang n aus den bekannten Daten der Stichprobe geschätzt. | |||
In einer Grundgesamtheit aus Berufstätigen beträgt der mit dem Emotion Regulation Questionnaire (ERQ) erfasste Mittelwert im kognitiven Umdeuten von stressigen Situationen im Alltag (Reappraisal) µ = 25. Die Standardabweichung in dieser Grundgesamtheit beträgt σ = 6. Zieht man aus dieser Grundgesamtheit 500 Zufallsstichproben der Größe n = 150, dann streuen die Mittelwerte der 500 Stichproben normalverteilt um den tatsächlichen Populationsmittelwert (vgl. Abb. 1). | In einer Grundgesamtheit aus Berufstätigen beträgt der mit dem Emotion Regulation Questionnaire (ERQ) erfasste Mittelwert im kognitiven Umdeuten von stressigen Situationen im Alltag (Reappraisal) µ = 25. Die Standardabweichung in dieser Grundgesamtheit beträgt σ = 6. Zieht man aus dieser Grundgesamtheit 500 Zufallsstichproben der Größe n = 150, dann streuen die Mittelwerte der 500 Stichproben normalverteilt um den tatsächlichen Populationsmittelwert (vgl. Abb. 1). | ||
[[File:1_2_Standardfehler.PNG|700px|Abbildung 1: Verteilung der Stichprobenmittelwerte und Darstellung des Standardfehlers]] | [[File:1_2_Standardfehler.PNG|700px|Abbildung 1: Verteilung der Stichprobenmittelwerte und Darstellung des Standardfehlers|link=Ausgelagerte_Bildbeschreibungen#Entstehung des Standardfehlers|Ausgelagerte Bildbeschreibung von Entstehung des Standardfehlers]] | ||
Da in diesem fiktiven Beispiel die Standardabweichung der Grundgesamtheit bekannt ist, kann der Standardfehler direkt aus der Standardabweichung σ = 6 und der Stichprobengröße n = 150 berechnet werden. Der Standardfehler des Mittelwerts beträgt hier σ<sub>X̅</sub> = 0.49. Die aus den Parametern der Stichproben ermittelte Standardabweichung der gezogenen Mittelwerte beträgt s<sub>(X̅)</sub> = 0.48 und weicht somit nur minimal von σ<sub>X̅</sub> ab. Bei einer geringeren Anzahl an Zufallsziehungen wäre diese Schätzung ungenauer. Die Standardabweichung der gezogenen 500 Mittelwerte s<sub>(X̅)</sub> darf nicht mit dem Standardfehler eines einzelnen Stichprobenmittelwertes s<sub>X̅</sub> verwechselt werden, welcher aus den Parametern s und n der einzelnen Stichprobe berechnet und in der Praxis für die Schätzung des Standardfehlers des arithmetischen Mittelwerts genutzt wird. | Da in diesem fiktiven Beispiel die Standardabweichung der Grundgesamtheit bekannt ist, kann der Standardfehler direkt aus der Standardabweichung σ = 6 und der Stichprobengröße n = 150 berechnet werden. Der Standardfehler des Mittelwerts beträgt hier σ<sub>X̅</sub> = 0.49. Die aus den Parametern der Stichproben ermittelte Standardabweichung der gezogenen Mittelwerte beträgt s<sub>(X̅)</sub> = 0.48 und weicht somit nur minimal von σ<sub>X̅</sub> ab. Bei einer geringeren Anzahl an Zufallsziehungen wäre diese Schätzung ungenauer. Die Standardabweichung der gezogenen 500 Mittelwerte s<sub>(X̅)</sub> darf nicht mit dem Standardfehler eines einzelnen Stichprobenmittelwertes s<sub>X̅</sub> verwechselt werden, welcher aus den Parametern s und n der einzelnen Stichprobe berechnet und in der Praxis für die Schätzung des Standardfehlers des arithmetischen Mittelwerts genutzt wird. | ||
[[Datei:Videolink_neu.PNG|link=http://141.76.19.82:3838/mediawiki/ | [[Datei:Videolink_neu.PNG|link=http://141.76.19.82:3838/mediawiki/MUVE_STAT/Videolinks/1_2_Standardfehler_Link.html | ||
|120px]] <span style="color: white"> kkk </span> Im [http://141.76.19.82:3838/mediawiki/ | |120px]] <span style="color: white"> kkk </span> Im [http://141.76.19.82:3838/mediawiki/MUVE_STAT/Videolinks/1_2_Standardfehler_Link.html Video] wird der Standardfehler näher erläutert. | ||
[[Datei:Simulationslink_neu2.PNG|link=http://141.76.19.82:3838/mediawiki/ | [[Datei:Simulationslink_neu2.PNG|link=http://141.76.19.82:3838/mediawiki/MUVE_STAT/Apps/1_2_Standardfehler/ | ||
|120px]] <span style="color: white"> kkk </span> Inwieweit der Standardfehler von verschiedenen Parametern abhängig ist, lässt sich in der [http://141.76.19.82:3838/mediawiki/ | |120px]] <span style="color: white"> kkk </span> Inwieweit der Standardfehler von verschiedenen Parametern abhängig ist, lässt sich in der [http://141.76.19.82:3838/mediawiki/MUVE_STAT/Apps/1_2_Standardfehler/ interaktiven Simulation] grafisch nachvollziehen. | ||
| Zeile 23: | Zeile 27: | ||
'''''Weiterführende Literatur''''' | '''''Weiterführende Literatur''''' | ||
Rudolf, M. | Rudolf, M. & Kuhlisch, W. (2020). ''Biostatistik. Eine Eine Einführung für Bio- und Umweltwissenschaftler'' (2. Aufl.). München: Pearson Studium. (Kapitel 4) | ||
Aktuelle Version vom 28. Februar 2023, 11:21 Uhr
Der Standardfehler ist eine sehr wichtige statistische Kenngröße, die die Grundlage vieler statistischer Tests darstellt, zum Beispiel in regressionsanalytischen Verfahren. In diesem Text und in der App wird exemplarisch auf den Standardfehler des Mittelwertes eingegangen. Der Standardfehler des Mittelwertes ist ein statistisches Maß für die Genauigkeit der Schätzung des Populationsmittelwertes. Er entspricht der Standardabweichung der Verteilungen der Punktschätzungen des Populationsmittelwertes von Stichproben des Umfangs n einer Population.
Der Standardfehler ist von der Standardabweichung in der Population und der Stichprobengröße abhängig und lässt sich mithilfe der folgenden Formel berechnen:
![]()
Ist die Streuung der Stichprobenmittelwerte um den Populationsmittelwert gering, kann der Populationsmittelwert genauer aus dem Mittelwert einer einzelnen Stichprobe geschätzt werden. Bei größerer Standardabweichung σ in der Population steigt demnach der Standardfehler an, wohingegen er bei größeren Stichprobenumfängen n geringer wird. Weil in der Praxis weder der Standardfehler des arithmetischen Mittelwertes noch die Standardabweichung aus der Population bekannt ist, wird der Standardfehler des Stichprobenmittelwertes sX̅ als Schätzwert für σX̅ verwendet. sX̅ wird dabei mithilfe der Standardabweichung s und dem Stichprobenumfang n aus den bekannten Daten der Stichprobe geschätzt.
In einer Grundgesamtheit aus Berufstätigen beträgt der mit dem Emotion Regulation Questionnaire (ERQ) erfasste Mittelwert im kognitiven Umdeuten von stressigen Situationen im Alltag (Reappraisal) µ = 25. Die Standardabweichung in dieser Grundgesamtheit beträgt σ = 6. Zieht man aus dieser Grundgesamtheit 500 Zufallsstichproben der Größe n = 150, dann streuen die Mittelwerte der 500 Stichproben normalverteilt um den tatsächlichen Populationsmittelwert (vgl. Abb. 1).
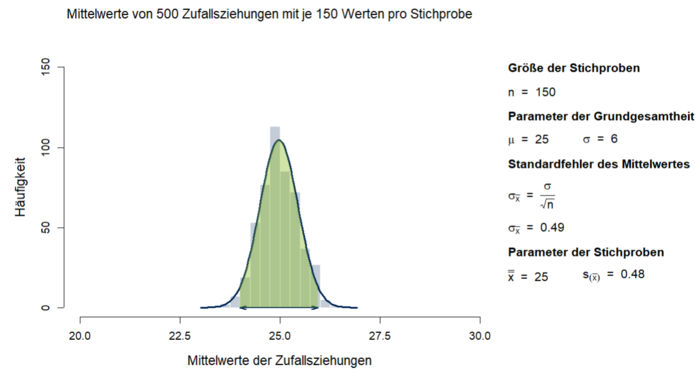
Da in diesem fiktiven Beispiel die Standardabweichung der Grundgesamtheit bekannt ist, kann der Standardfehler direkt aus der Standardabweichung σ = 6 und der Stichprobengröße n = 150 berechnet werden. Der Standardfehler des Mittelwerts beträgt hier σX̅ = 0.49. Die aus den Parametern der Stichproben ermittelte Standardabweichung der gezogenen Mittelwerte beträgt s(X̅) = 0.48 und weicht somit nur minimal von σX̅ ab. Bei einer geringeren Anzahl an Zufallsziehungen wäre diese Schätzung ungenauer. Die Standardabweichung der gezogenen 500 Mittelwerte s(X̅) darf nicht mit dem Standardfehler eines einzelnen Stichprobenmittelwertes sX̅ verwechselt werden, welcher aus den Parametern s und n der einzelnen Stichprobe berechnet und in der Praxis für die Schätzung des Standardfehlers des arithmetischen Mittelwerts genutzt wird.
![]() kkk Im Video wird der Standardfehler näher erläutert.
kkk Im Video wird der Standardfehler näher erläutert.
![]() kkk Inwieweit der Standardfehler von verschiedenen Parametern abhängig ist, lässt sich in der interaktiven Simulation grafisch nachvollziehen.
kkk Inwieweit der Standardfehler von verschiedenen Parametern abhängig ist, lässt sich in der interaktiven Simulation grafisch nachvollziehen.
Weiterführende Literatur
Rudolf, M. & Kuhlisch, W. (2020). Biostatistik. Eine Eine Einführung für Bio- und Umweltwissenschaftler (2. Aufl.). München: Pearson Studium. (Kapitel 4)