Einfache lineare Regression bei dichotomen bzw. kategorialen Prädiktor
In linearen Regressionsanalysen kann der Einfluss nominalskalierter, also dichotomer oder kategorialer Variablen auf das Kriterium durch entsprechende Kodierungen von Dummyvariablen bestimmt werden.
Eine Variable wird als nominalskaliert bezeichnet, wenn ihre Ausprägungen in Form von diskreten Kategorien vorliegen und dabei keiner Ordnung bzw. Rangreihe unterliegen. Mithilfe verschiedener Kodierungen können auch nominalskalierte Variablen im Rahmen einer Regressionsanalyse zur Vorhersage eines metrischen Kriteriums verwendet werden. Häufig angewandte Kodierungen sind die Dummykodierung, die Effektkodierung, die Helmertkodierung oder die umgekehrte Helmertkodierung, welche jeweils unterschiedliche Rückschlüsse erlauben. Bei all diesen werden c-1 Kodiervariablen benötigt, wobei c der Anzahl der Kategorien der Variablen entspricht.
Beispielstudie
Im Folgenden sollen die verschiedenen Kodiermöglichkeiten anhand eines Beispiels genauer erläutert werden. In einer fiktiven Studie wird der Einfluss verschiedener Pausenregelungen auf die Produktivität der Mitarbeiter am Arbeitsplatz untersucht. Dafür werden die Mitarbeiter eines Unternehmens in drei verschiedene Gruppen eingeteilt. Gruppe 1 hat neben der gesetzlich festgelegten Mittagspause keine zusätzlichen Pausenzeiten. In Gruppe 2 gibt es zusätzlich zur Mittagspause täglich zwei 15-Minuten Pausen. In Gruppe 3 erhalten die Mitarbeiter ebenfalls zwei zusätzliche Pausen, in denen einfache Bewegungsübungen mit ihnen durchgeführt werden. Die Produktivität wird mit einer standardisierten Skala mit einem Mittelwert von 100 erfasst. In Abbildung 1 werden die Mittelwerte der Produktivität der Mitarbeiter in den verschiedenen Gruppen gegenübergestellt.
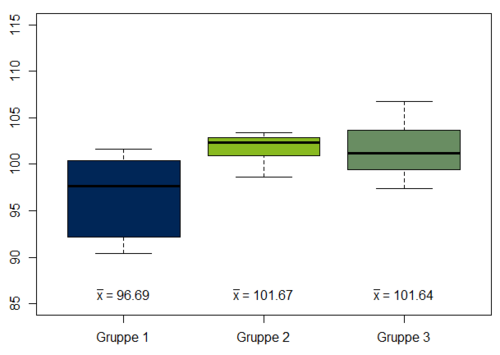
Da die Prädiktorvariable im vorliegenden Beispiel drei Kategorien enthält, werden zwei Dummyvariablen benötigt. Die allgemeine Regressionsgleichung der einfachen linearen Regression wäre dementsprechend Produktivitäti= b0 + b1 · Dummy1i + b2 · Dummy2i + ei. Die Werte der Dummyvariablen und die daraus geschätzten Regressionskoeffizienten (inkl. der Konstante) unterscheiden sich je nach ausgewählter Kodierung.
Bei der Indikator- oder Dummykodierung gibt es eine Referenzkategorie, in der beide Dummyvariablen den Wert 0 erhalten. sodass der Wert der Konstante dem Mittelwert des Kriteriums in der Referenzgruppe entspricht. Im beschriebenen Beispiel wird Gruppe 1 als Referenzgruppe festgelegt, sodass die geschätzte Konstante dem Mittelwert der Produktivität entspricht, wenn keine zusätzlichen Pausen eingebaut werden (b0 = 96.69, vgl. Abbildung 1). Personen der Gruppe 2 erhalten in der ersten Dummyvariable eine 1 und in der zweiten eine 0 und Personen der Gruppe 3 genau andersherum. So entsprechen die Regressionskoeffizienten b1 und b2 der Mittelwertsdifferenz der jeweiligen Gruppe von der Referenzgruppe. Der erste Regressionskoeffizient (b1 = 4.98) bedeutet also zum Beispiel, dass der Mittelwert der ersten Pausengruppe um 4.98 höher ist als der Mittelwert der Referenzgruppe (p < 0.001). Mit der Dummykodierung können nur die Mittelwertsunterschiede zur Referenzgruppe statistisch abgesichert werden. Wäre man daran interessiert, die Gruppen 2 und 3 miteinander zu vergleichen, müsste eine andere Referenzgruppe festgelegt werden oder die Helmertkodierung verwendet werden.
Bei der Effektkodierung erhalten beide Dummyvariablen im Unterschied zur Dummykodierung eine -1 in der Referenzkategorie. Die anderen beiden Gruppen werden analog mit 0 und 1 kodiert. Die Regressionskonstante der Effektkodierung entspricht dem Mittelwert der Gruppenmittelwerte, welcher im Beispiel b0 = 100 ist. Bei unterschiedlich großen Gruppen kann dieser vom Gesamtmittelwert abweichen. Die weiteren Regressionskoeffizienten entsprechen der Abweichung des jeweiligen Gruppenmittelwertes von b0. So wird in einer Regression mit Effektkodierung inferenzstatistisch überprüft, ob der Mittelwert einer Gruppe vom Mittelwert der Gruppenmittelwerte abweicht. Dies kann nicht für die Referenzkategorie überprüft werden. Im Beispiel hat Gruppe 2 einen inferenzstatistisch abgesichert höheren Mittelwert (p < 0.05), Gruppe 3 jedoch nicht (p = 0.062).
Auch mit der Helmertkodierung und der umgekehrten Helmertkodierung können die Gruppen für spezielle Fragestellungen untereinander verglichen werden. Bei der Helmertkodierung erhält die erste Dummyvariable für Gruppe 1 den Wert 2/3 und für die anderen beiden Gruppen den Wert -1/3, sodass der Unterschied der ersten Gruppe zu den anderen beiden Gruppen analysiert werden kann. Im vorliegenden Beispiel bedeutet der Regressionskoeffizient b1 = -4.96, dass der Mittelwert der Kontrollgruppe um 4.96 geringer ist als der Mittelwert der Mittelwerte der anderen beiden Gruppen (p < 0.001). In der zweiten Dummyvariable erhält die Referenzgruppe den Wert 0 und die anderen Gruppen die Werte 0.5 und -0.5. Mit dieser kann der Unterschied zwischen Gruppe 2 und Gruppe 3 untersucht werden. Dieser ist im Beispiel sehr gering (b2 = 0.04) und nicht signifikant von 0 verschieden (p = 0.98). Die Summe der Koeffizienten beider Dummyvariablen ergibt dabei immer 0. Bei der umgekehrten Helmertkodierung werden die Gruppen andersherum kodiert, sodass der Mittelwert einer Gruppe mit dem Mittelwert der Mittelwerte aller vorhergehenden Gruppen verglichen wird. Im Beispiel würde Dummyariable 1 die Gruppe 3 mit dem Durchschnitt der Mittelwerte der Gruppen 1 und 2 vergleichen und Dummyvariable 2 die Mittelwerte der Gruppen 1 und 2.
![]() kkk Im Video wird das Prinzip der einfachen linearen Regression mit nominalskalierten Variablen näher erläutert.
kkk Im Video wird das Prinzip der einfachen linearen Regression mit nominalskalierten Variablen näher erläutert.
![]() kkk In der interaktiven Simulation können Regressionen mit einem dichotomen bzw. kategorialen Prädiktor für die verschiedenen Kodierungsmöglichkeiten grafisch veranschaulicht werden.
kkk In der interaktiven Simulation können Regressionen mit einem dichotomen bzw. kategorialen Prädiktor für die verschiedenen Kodierungsmöglichkeiten grafisch veranschaulicht werden.
Weiterführende Literatur
Bortz, J., & Schuster, C. (2016). Statistik für Human- und Sozialwissenschaftler. Berlin: Springer.
Eid, M., Gollwitzer, M., & Schmitt, M. (2017). Statistik und Forschungsmethoden. Weinheim: Beltz.
Rudolf, M. & Buse, J. (2020). Multivariate Verfahren. Eine praxisorientierte Einführung mit Anwendungsbeispielen (3. Aufl., Kapitel 3.1.5). Göttingen: Hogrefe.