Genetische Algorithmen
Intuition genetischer Algorithmen
Das grundlegende Prinzip dieser Art von Optimierungsverfahren ist an die Prinzipien der Evolutionstheorie angelehnt: So wie evolutionäre Prozesse in der biologischen Entwicklung Individuen hervorbringen, die in ihren Eigenschaften möglichst gut an ihre ökologische Nische angepasst sind, bringen sie bei der Parametersuche Modelle hervor, die in ihren Parametern möglichst optimal an die Daten angepasst sind.
Um konkret ein Beispiel aus dem Tierreich zu nennen, könnten wir eine Gruppe von Hasen betrachten, die unterschiedlich lange Ohren und unterschiedliche Fellfarben haben. Diese Merkmale bestimmen die Fitness, also die Überlebenswahrscheinlichkeit der Hasen in ihrer Nische, z.B. einem Wald. Ein Hase mit weißem Fell kann sich beispielsweise schlechter im Wald tarnen und wird deshalb vielleicht eher gefressen. Dies führt zu natürlicher Selektion: Nur Hasen, die nicht gefressen werden, können Nachkommen bekommen, die die Eigenschaften der Eltern in neuer Kombination und mit eigenen Mutationen tragen. Schrittweise entstehen so immer besser an die Umwelt angepasste Hasen.
Ein Individuum mit einer bestimmten Kombination von Eigenschaften entspricht beim Data Fitting mit genetischen Algorithmen einem Punkt auf der Fehleroberfläche für eine bestimmte Kombination von Parameterwerten des Modells. Die Fitness wiederum stellt der Wert der Fehlerfunktion beim Vergleich mit konkreten Daten dar. Der Algorithmus selektiert aus einer Gruppe von Individuen – der Population – die fittesten Parameterkombinationen und erstellt aus ihnen neue Individuen, die die erfolgreichen Parameterkombination neu kombinieren und mutieren. So entwickelt der Algorithmus über viele Generationen schließlich Parameterkombinationen, die die Fitness maximieren.
Ablauf des Algorithmus
- Festlegung einer Grundpopulation
Zuerst wird eine Gruppe von Individuen (das heißt Parameterkombinationen des Modells) festgelegt. Diese bilden die erste Generation. Die Auswahl dieser Parameterkombinationen erfolgt zufällig und/oder versucht einen möglichst großen Raum verschiedener Kombinationen abzudecken. - Berechnung der Fitness
Für jedes Mitglied der Population wird der Wert der Fehlerfunktion berechnet. - Selektion der besten Individuen
Die Punkte mit den besten Fehlerfunktionswerten, also der größten Fitness, werden ausgewählt, um sich zu reproduzieren. Das bedeutet, dass neue Punkte aus den Parametern ausgewählter Punkte generiert werden. - Ableitung der nächsten Generation
Hierfür gibt es drei der Biologie entlehnte Mechanismen, nämlich Rekombination, Mutation und Reproduktion. Rekombination bedeutet, dass die Parameter zweier Punkte gemischt werden, sodass ein neuer Punkt entsteht. Zusätzlich werden Mutationen vorgenommen, durch die ein Merkmal innerhalb eines Individuums zufällig verändert wird. Die besten Individuen können außerdem reproduziert, das heißt, in die neue Generation unverändert übernommen werden, um ein bisher gefundenes Optimum zu behalten. So entsteht eine neue Generation der Population.
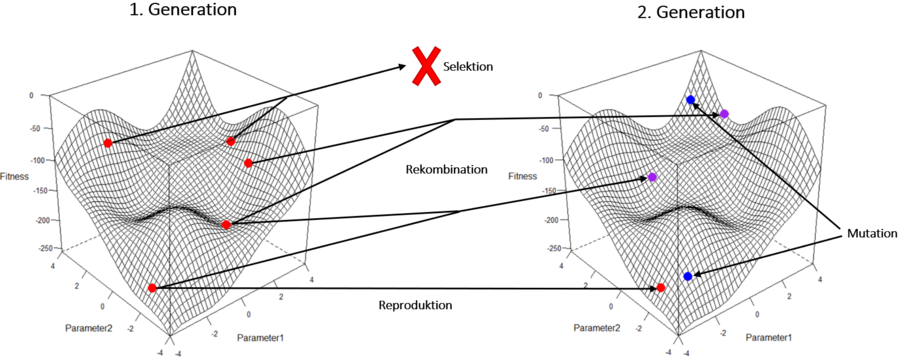
- Das Vorgehen ab 2. wird für die neue Generation wiederholt, bis ein Abbruchkriterium erreicht wird, welches bestimmt, dass ein Individuum der Population den erstrebten maximalen Fitnesswert erreicht hat oder eine bestimmte Anzahl an Generationen berechnet wurde.
Vor- und Nachteile genetischer Algorithmen
Genetische Algorithmen sind nur in relativ geringem Maße anfällig für lokale Minima, da die Fehleroberfläche an vielen Punkten evaluiert wird und neue Punkte durch Mutation unabhängig von einem vorherigen Wert erschlossen werden können. Es ist daher auch weniger wichtig als zum Beispiel beim Gradient Descent, wo die Startwerte gesetzt werden. Nachteilig ist wie bei anderen Algorithmen auch, dass das Finden des Minimums nicht garantiert ist. Es sollten deshalb mehrere Startpopulationen genutzt werden. Zudem können ungünstige Einstellungen des Algorithmus problematisch sein. Wird beispielsweise die Mutationsrate zu hoch gewählt, werden Punkte eher zufällig auf der Fehleroberfläche verteilt, ohne bisherigen guten Parameterkombinationen Beachtung zu schenken. Bei einer zu geringen Mutationsrate hingegen kann es sein, dass die Populationsmitglieder sich so ähnlich sind, dass ein lokales Minimum nicht verlassen wird. Schließlich sind genetische Algorithmen sehr rechenaufwändig, da in jeder Generation alle Individuen (oft mehr als 100) evaluiert, also simuliert, werden müssen.
![]() kkk Das Verhalten eines genetischen Algorithmus kann in der R-Shiny-App "Fitting" beobachtet und untersucht werden.
kkk Das Verhalten eines genetischen Algorithmus kann in der R-Shiny-App "Fitting" beobachtet und untersucht werden.