General Linear Model: Unterschied zwischen den Versionen
Wehner (Diskussion | Beiträge) Keine Bearbeitungszusammenfassung |
Keine Bearbeitungszusammenfassung |
||
| (11 dazwischenliegende Versionen von 2 Benutzern werden nicht angezeigt) | |||
| Zeile 1: | Zeile 1: | ||
{{Nav|Navigation|Kognitive Modellierung|Hauptseite}} | {{Nav|Navigation|Statistische Modelle|Kognitive Modellierung|Hauptseite}} | ||
Das General Linear Model (dt. Allgemeines Lineares Modell, ALM) ist ein grundlegendes Modell der Statistik, auf welchem eine Vielzahl häufig eingesetzter Verfahren, wie z.B. die Varianzanalyse, die Regressionsanalyse und viele weitere Verfahren basieren. Sie alle stellen Spezialfälle des GLM dar. | Das General Linear Model (dt. Allgemeines Lineares Modell, ALM) ist ein grundlegendes Modell der Statistik, auf welchem eine Vielzahl häufig eingesetzter Verfahren, wie z.B. die Varianzanalyse, die Regressionsanalyse und viele weitere Verfahren basieren. Sie alle stellen Spezialfälle des GLM dar. | ||
| Zeile 6: | Zeile 6: | ||
Formal lässt sich das GLM durch die folgende Gleichung beschreiben: | Formal lässt sich das GLM durch die folgende Gleichung beschreiben: | ||
:: [[Datei:GLM_1.png|link=Ausgelagerte_Formeln#General Linear Model 1|Ausgelagerte Formel General Linear Model 1]] | |||
b... Vektor der Gewichte aller Prädiktoren | :: Y... Vektor der Kriteriumsvariablen | ||
:: X... Matrix der Prädiktoren (= Designmatrix) | |||
:: b... Vektor der Gewichte aller Prädiktoren | |||
:: e... Vektor der Residuen | |||
Die gleichzeitige Betrachtung der Werte mehrerer Beobachtungseinheiten (z.B. Individuen) führt zu einem linearen Gleichungssystem, welches mit Hilfe eines Minimierungsprinzips (dem Prinzip der Kleinsten Quadrate) die Schätzung der gesuchten Prädiktorgewichte b ermöglicht. Die Modellparameter werden dabei so gewählt, dass die Summe der quadrierten Fehler (= Abweichungen der beobachteten Y-Werte von den durch das Modell vorhergesagten Kriteriumswerten Xb) ein Minimum erreicht: | Die gleichzeitige Betrachtung der Werte mehrerer Beobachtungseinheiten (z.B. Individuen) führt zu einem linearen Gleichungssystem, welches mit Hilfe eines Minimierungsprinzips (dem Prinzip der Kleinsten Quadrate) die Schätzung der gesuchten Prädiktorgewichte b ermöglicht. Die Modellparameter werden dabei so gewählt, dass die Summe der quadrierten Fehler (= Abweichungen der beobachteten Y-Werte von den durch das Modell vorhergesagten Kriteriumswerten Xb) ein Minimum erreicht: | ||
: n... Anzahl an Individuen | :: [[Datei:GLM_2.png|link=Ausgelagerte_Formeln#General Linear Model 2|Ausgelagerte Formel General Linear Model 2]] | ||
:: n... Anzahl an Individuen | |||
Als beste Schätzung für b erhält man durch Formelumstellung: | Als beste Schätzung für b erhält man durch Formelumstellung: | ||
[[Datei:GLM_20.PNG]] | :: [[Datei:GLM_3.png|link=Ausgelagerte_Formeln#General Linear Model 3|Ausgelagerte Formel General Linear Model 3]] | ||
:: [[Datei:GLM_20.PNG|Das Bild ist Bestandteil der vorhergehenden Formel und wurde bereits dort beschrieben]] | |||
Sofern die Inverse von [[Datei: | Sofern die Inverse von [[Datei:GLM_21.png|$X^{T} \cdot X$]] existiert, kann diese Gleichung immer gelöst werden. | ||
Ein Vergleich der beobachteten Daten und der Linearkombination aller verwendeten Prädiktoren ermöglicht die Einschätzung der Güte des linearen Zusammenhangs. Dazu verwendet man üblicherweise das Bestimmtheitsmaß R², welches den Anteil der Variabilität im Modell angibt, der durch die ausgewählten Prädiktoren erklärt werden kann. Bei mehreren Prädiktoren wird dabei oft eine korrigierte Form des Bestimmtheitsmaßes gewählt, welche die Anzahl der Prädiktoren bestrafend mit verrechnet. | Ein Vergleich der beobachteten Daten und der Linearkombination aller verwendeten Prädiktoren ermöglicht die Einschätzung der Güte des linearen Zusammenhangs. Dazu verwendet man üblicherweise das Bestimmtheitsmaß R², welches den Anteil der Variabilität im Modell angibt, der durch die ausgewählten Prädiktoren erklärt werden kann. Bei mehreren Prädiktoren wird dabei oft eine korrigierte Form des Bestimmtheitsmaßes gewählt, welche die Anzahl der Prädiktoren bestrafend mit verrechnet. | ||
Spezialfälle des Modells sind der t-Test, die Varianzanalyse, Korrelations- und Regressionsrechnungen sowie Kovarianzanalysen. Die Einteilung dieser Spezialfälle wird anhand der Anzahl von Prädiktor- und Kriteriumsvariablen und dem Skalenniveau der Variablen vorgenommen. | Spezialfälle des Modells sind der t-Test, die Varianzanalyse, Korrelations- und Regressionsrechnungen sowie Kovarianzanalysen. Die Einteilung dieser Spezialfälle wird anhand der Anzahl von Prädiktor- und Kriteriumsvariablen und dem Skalenniveau der Variablen vorgenommen. | ||
'''''Folgende Darstellung zeigt den t-Test als Spezialfall des GLM:''''' | |||
Das GLM stellt das übergeordnete Modell des t-Test dar. Es prüft z.B. den linearen Einfluss einer Prädiktorvariable auf eine Kriteriumsvariable mithilfe der folgenden Formel: | |||
:: [[Datei:GLM_22.PNG|link=Ausgelagerte_Formeln#t-Test als Spezialfall des GLM|Ausgelagerte Formel t-Test Modell]] | |||
Einen speziellen Fall stellt der Vergleich zweier Gruppen dar. Dieser Gruppenvergleich erfolgt üblicherweise mittels eines t-Tests. Dieser stellt die Frage, ob der Unterschied zwischen zwei Gruppen bedeutsam ist. Die Gruppenzugehörigkeit kann dabei als Prädiktor für die untersuchte Kriteriumsvariable, welche zwischen beiden Gruppen verglichen werden soll, betrachtet werden. | |||
Die Prüfgröße des t-Test wird dabei folgendermaßen ermittelt: | |||
:: Prüfgröße [[Datei:GLM_12.png|link=Ausgelagerte_Formeln#Prüfgröße t|Ausgelagerte Formel Prüfgröße t]] | |||
:: [[Datei:GLM_23.PNG|Das Bild ist Bestandteil der vorhergehenden Formel und wurde bereits dort beschrieben]] | |||
Es fließen somit die Mittelwerte beider Gruppen in die Berechnung der Prüfgröße ein. Diese Mittelwertdifferenz kann auch in der Formel des GLM abgebildet werden. | |||
Die Verwendung der Formel des GLM würde wie folgt aussehen: | |||
Es gilt: | |||
::::{| | |||
| [[Datei:GLM_16.png|$b_0=x_1$]] | |||
| | |||
| | |||
|- | |||
| [[Datei:GLM_17.png|$x=g$]] | |||
| | |||
| - Prädiktorvariable mit zwei Ausprägungen - bildet '''''Gruppenzugehörigkeit''''' ab | |||
|- | |||
| [[Datei:GLM_18.png|$b_1=\Delta(x_1x_2)$]] | |||
| | |||
| - Differenz der Gruppenmittelwerte | |||
|} | |||
Daraus folgt: | |||
:::: [[Datei:GLM_19.png|link=Ausgelagerte_Formeln#General Linear Model 4|Ausgelagerte Formel GLM 4]] | |||
:::::mit g = 0 für Mittelwert der Gruppe 1 | |||
:::::und g = 1 für Mittelwert der Gruppe 2 | |||
Aktuelle Version vom 10. Dezember 2021, 16:52 Uhr
Das General Linear Model (dt. Allgemeines Lineares Modell, ALM) ist ein grundlegendes Modell der Statistik, auf welchem eine Vielzahl häufig eingesetzter Verfahren, wie z.B. die Varianzanalyse, die Regressionsanalyse und viele weitere Verfahren basieren. Sie alle stellen Spezialfälle des GLM dar.
Es ermöglicht die Beschreibung der Ausprägungen einer oder mehrerer Kriteriumsvariablen (= abhängiger Variablen) durch eine Linearkombination (gewichtete Summe) von Prädiktorvariablen (= unabhängiger Variablen) und einer Fehlerkomponente (Residuum). Die unabhängigen Variablen bilden den Ausgangspunkt für die Vorhersage und werden daher Prädiktoren genannt. Die abhängige Variable, dessen Ausprägung man vorhersagen möchte, wird in der Psychologie als Kriteriumsvariable bezeichnet. Grundvoraussetzung für die Anwendung des Modells ist die Annahme, dass ein linearer Zusammenhang zwischen den zu erklärenden Beobachtungsdaten und den bekannten Einflussvariablen (Prädiktoren / Regressoren) besteht.
Formal lässt sich das GLM durch die folgende Gleichung beschreiben:
- Y... Vektor der Kriteriumsvariablen
- X... Matrix der Prädiktoren (= Designmatrix)
- b... Vektor der Gewichte aller Prädiktoren
- e... Vektor der Residuen
Die gleichzeitige Betrachtung der Werte mehrerer Beobachtungseinheiten (z.B. Individuen) führt zu einem linearen Gleichungssystem, welches mit Hilfe eines Minimierungsprinzips (dem Prinzip der Kleinsten Quadrate) die Schätzung der gesuchten Prädiktorgewichte b ermöglicht. Die Modellparameter werden dabei so gewählt, dass die Summe der quadrierten Fehler (= Abweichungen der beobachteten Y-Werte von den durch das Modell vorhergesagten Kriteriumswerten Xb) ein Minimum erreicht:
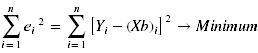
- n... Anzahl an Individuen
Als beste Schätzung für b erhält man durch Formelumstellung:

Sofern die Inverse von ![]() existiert, kann diese Gleichung immer gelöst werden.
existiert, kann diese Gleichung immer gelöst werden.
Ein Vergleich der beobachteten Daten und der Linearkombination aller verwendeten Prädiktoren ermöglicht die Einschätzung der Güte des linearen Zusammenhangs. Dazu verwendet man üblicherweise das Bestimmtheitsmaß R², welches den Anteil der Variabilität im Modell angibt, der durch die ausgewählten Prädiktoren erklärt werden kann. Bei mehreren Prädiktoren wird dabei oft eine korrigierte Form des Bestimmtheitsmaßes gewählt, welche die Anzahl der Prädiktoren bestrafend mit verrechnet.
Spezialfälle des Modells sind der t-Test, die Varianzanalyse, Korrelations- und Regressionsrechnungen sowie Kovarianzanalysen. Die Einteilung dieser Spezialfälle wird anhand der Anzahl von Prädiktor- und Kriteriumsvariablen und dem Skalenniveau der Variablen vorgenommen.
Folgende Darstellung zeigt den t-Test als Spezialfall des GLM:
Das GLM stellt das übergeordnete Modell des t-Test dar. Es prüft z.B. den linearen Einfluss einer Prädiktorvariable auf eine Kriteriumsvariable mithilfe der folgenden Formel:

Einen speziellen Fall stellt der Vergleich zweier Gruppen dar. Dieser Gruppenvergleich erfolgt üblicherweise mittels eines t-Tests. Dieser stellt die Frage, ob der Unterschied zwischen zwei Gruppen bedeutsam ist. Die Gruppenzugehörigkeit kann dabei als Prädiktor für die untersuchte Kriteriumsvariable, welche zwischen beiden Gruppen verglichen werden soll, betrachtet werden.
Die Prüfgröße des t-Test wird dabei folgendermaßen ermittelt:
- Prüfgröße
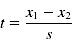
- Prüfgröße

Es fließen somit die Mittelwerte beider Gruppen in die Berechnung der Prüfgröße ein. Diese Mittelwertdifferenz kann auch in der Formel des GLM abgebildet werden.
Die Verwendung der Formel des GLM würde wie folgt aussehen:
Es gilt:
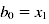
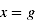
- Prädiktorvariable mit zwei Ausprägungen - bildet Gruppenzugehörigkeit ab 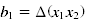
- Differenz der Gruppenmittelwerte
Daraus folgt:
- mit g = 0 für Mittelwert der Gruppe 1
- und g = 1 für Mittelwert der Gruppe 2