Kognitive Modelle: Unterschied zwischen den Versionen
Wehner (Diskussion | Beiträge) Keine Bearbeitungszusammenfassung |
Paul (Diskussion | Beiträge) (→Box-Pfeil-Modelle: Gedächtnismodell von Atkinson & Shiffrin link einfügen pb) |
||
| (9 dazwischenliegende Versionen von 3 Benutzern werden nicht angezeigt) | |||
| Zeile 1: | Zeile 1: | ||
{{Nav|Navigation|Kognitive Modellierung|Hauptseite}} | {{Nav|Navigation|Mathematische Modelle|Kognitive Modellierung|Hauptseite}} | ||
Kognitive Modelle sind der Versuch einer Annäherung an reale kognitive Phänomene um diese besser verstehen und vorhersagen zu können. Im Gegensatz zu [[Kognitive Architekturen|Kognitiven Architekturen]] sind sie stärker auf einzelne kognitive Prozesse (z.B. Visuelle Suche, Gedächtnisenkodierung) bzw. auf die Interaktion weniger Prozesse (Visuelle Suche und Belohnung) oder auf die Verhaltensvorhersage für eine spezifische Aufgabe fokussiert. Kognitive Architekturen dagegen legen den Schwerpunkt auf die grundlegenden strukturellen Eigenschaften eines kognitiven Systems, wodurch sie kognitive Modelle, die innerhalb der Architektur formuliert werden, beschränken können. Andersherum können kognitive Modelle dabei helfen, die Grenzen und Fehler von kognitiven Architekturen aufdecken. | Kognitive Modelle sind der Versuch einer Annäherung an reale kognitive Phänomene um diese besser verstehen und vorhersagen zu können. Im Gegensatz zu [[Kognitive Architekturen|Kognitiven Architekturen]] sind sie stärker auf einzelne kognitive Prozesse (z.B. Visuelle Suche, Gedächtnisenkodierung) bzw. auf die Interaktion weniger Prozesse (Visuelle Suche und Belohnung) oder auf die Verhaltensvorhersage für eine spezifische Aufgabe fokussiert. Kognitive Architekturen dagegen legen den Schwerpunkt auf die grundlegenden strukturellen Eigenschaften eines kognitiven Systems, wodurch sie kognitive Modelle, die innerhalb der Architektur formuliert werden, beschränken können. Andersherum können kognitive Modelle dabei helfen, die Grenzen und Fehler von kognitiven Architekturen aufdecken. | ||
| Zeile 7: | Zeile 8: | ||
== Box-Pfeil-Modelle == | == Box-Pfeil-Modelle == | ||
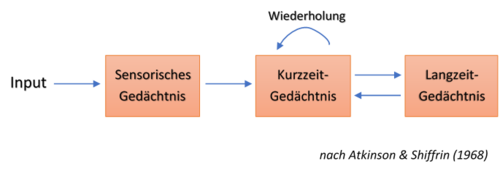
Viele klassische Modelle der Kognitionspsychologie (oder der Psycholinguistik) stellen kognitive Prozesse in Form von Box-Pfeil Diagrammen dar (wie z.B. das | Viele klassische Modelle der Kognitionspsychologie (oder der Psycholinguistik) stellen kognitive Prozesse in Form von Box-Pfeil Diagrammen dar (wie z.B. das [https://de.wikipedia.org/wiki/Drei-Speicher-Modell Gedächtnismodell von Atkinson & Shiffrin] von 1968, s.u.). In den Boxen finden sich dabei die Stufen der Repräsentation oder Informationsverarbeitung (z.B. sensorische Verarbeitung - Integration der Inputs – Entscheidung – Reaktion) und die Pfeile repräsentieren ihre Zusammenhänge (z.B. die Richtung der Prozessabläufe) oder zusätzliche Prozesse. Hier werden also hypothetische Informationsverarbeitungsprozesse innerhalb einer bestimmten kognitiven Funktion in einer Weise expliziert, wie man es von Computer Ablaufdiagrammen kennt. In der Anzahl und Vernetzung der Boxen zeigen sich dabei sehr große Unterschiede zwischen den Modellen. | ||
[[Datei:Kognitive-Modelle BoxPfeil.png||500px|link=Ausgelagerte_Bildbeschreibungen#Gedächtnismodell_von_Atkinson_&_Shiffrin |Ausgelagerte Bildbeschreibung von Gedächtnismodell von Atkinson & Shiffrin ]] | |||
== Mathematische Kognitive Modelle: Theory of Visual Attention (TVA) == | == Mathematische Kognitive Modelle: Theory of Visual Attention (TVA) == | ||
| Zeile 22: | Zeile 22: | ||
Die TVA beschreibt die Erkennung und Selektion von Objekten/Items im visuelles Feld als Durchführung von perzeptuellen Kategorisierungen. Die Erkennung und Selektion eines Objekts basiert dabei auf dem Wettbewerb zwischen verschiedenen Kategorisierungsmöglichkeiten. Dazu werden zunächst die Gewichte w aller im rezeptiven Feld befindlichen Items x mittels folgender Formel berechnet: | Die TVA beschreibt die Erkennung und Selektion von Objekten/Items im visuelles Feld als Durchführung von perzeptuellen Kategorisierungen. Die Erkennung und Selektion eines Objekts basiert dabei auf dem Wettbewerb zwischen verschiedenen Kategorisierungsmöglichkeiten. Dazu werden zunächst die Gewichte w aller im rezeptiven Feld befindlichen Items x mittels folgender Formel berechnet: | ||
[[Datei: | ::[[Datei:Kognitive-Modelle F1.png||600px|link=Ausgelagerte_Formeln#TVA 1|Ausgelagerte Formel TVA 1]] | ||
R steht dabei für die Menge aller möglichen Kategorien. Eine visuelle Kategorie j kann beispielsweise eine bestimmte Farbe, Form oder Orientierung sein. Der Term η(x,j) repräsentiert die sensorische Evidenz dafür, dass das Item x zur Kategorie j gehört. Diese sensorische Evidenz kann z.B. durch eine verschwommene Darstellung vermindert oder aber durch Ähnlichkeit zu anderen Items dieser Kategorie erhöht sein. Die Relevanz der Kategorie j für den Beobachter ist πj. | R steht dabei für die Menge aller möglichen Kategorien. Eine visuelle Kategorie j kann beispielsweise eine bestimmte Farbe, Form oder Orientierung sein. Der Term η(x,j) repräsentiert die sensorische Evidenz dafür, dass das Item x zur Kategorie j gehört. Diese sensorische Evidenz kann z.B. durch eine verschwommene Darstellung vermindert oder aber durch Ähnlichkeit zu anderen Items dieser Kategorie erhöht sein. Die Relevanz der Kategorie j für den Beobachter ist πj. | ||
| Zeile 28: | Zeile 28: | ||
Die Verarbeitungsgeschwindigkeit einer Itemkategorisierung berechnet sich im Anschluss folgendermaßen: | Die Verarbeitungsgeschwindigkeit einer Itemkategorisierung berechnet sich im Anschluss folgendermaßen: | ||
[[Datei: | ::[[Datei:Kognitive-Modelle F2.png||600px|link=Ausgelagerte_Formeln#TVA 2|Ausgelagerte Formel TVA 2]] | ||
Die Verarbeitungsgeschwindigkeit v(x,j) entspricht der Wahrscheinlichkeit, dass ein Item x als Element der Kategorie j kategorisiert wird. Sie berechnet sich als Produkt der sensorischen Evidenz η(x,j), dass ein Item x zur Kategorie j gehört, dem Bias βj einer Person, Items der Kategorie j zuzuordnen und dem Anteil des Gewichts von Item j am Gesamtgewicht aller Items (Gesamtheit aller Items = S). | Die Verarbeitungsgeschwindigkeit v(x,j) entspricht der Wahrscheinlichkeit, dass ein Item x als Element der Kategorie j kategorisiert wird. Sie berechnet sich als Produkt der sensorischen Evidenz η(x,j), dass ein Item x zur Kategorie j gehört, dem Bias βj einer Person, Items der Kategorie j zuzuordnen und dem Anteil des Gewichts von Item j am Gesamtgewicht aller Items (Gesamtheit aller Items = S). | ||
Aktuelle Version vom 20. Dezember 2021, 19:54 Uhr
Kognitive Modelle sind der Versuch einer Annäherung an reale kognitive Phänomene um diese besser verstehen und vorhersagen zu können. Im Gegensatz zu Kognitiven Architekturen sind sie stärker auf einzelne kognitive Prozesse (z.B. Visuelle Suche, Gedächtnisenkodierung) bzw. auf die Interaktion weniger Prozesse (Visuelle Suche und Belohnung) oder auf die Verhaltensvorhersage für eine spezifische Aufgabe fokussiert. Kognitive Architekturen dagegen legen den Schwerpunkt auf die grundlegenden strukturellen Eigenschaften eines kognitiven Systems, wodurch sie kognitive Modelle, die innerhalb der Architektur formuliert werden, beschränken können. Andersherum können kognitive Modelle dabei helfen, die Grenzen und Fehler von kognitiven Architekturen aufdecken.
Kognitive Modelle stammen traditionell aus der Kognitionspsychologie, werden aber zunehmend aus den Bereichen des maschinellen Lernens und der Künstlichen Intelligenz heraus entwickelt. Die vielen unterschiedlichen Arten von kognitiven Modellen reichen von Box-Pfeil Diagrammen über dynamische Differentialgleichungsmodelle zu komplexen komputationalen Theorien.
Box-Pfeil-Modelle
Viele klassische Modelle der Kognitionspsychologie (oder der Psycholinguistik) stellen kognitive Prozesse in Form von Box-Pfeil Diagrammen dar (wie z.B. das Gedächtnismodell von Atkinson & Shiffrin von 1968, s.u.). In den Boxen finden sich dabei die Stufen der Repräsentation oder Informationsverarbeitung (z.B. sensorische Verarbeitung - Integration der Inputs – Entscheidung – Reaktion) und die Pfeile repräsentieren ihre Zusammenhänge (z.B. die Richtung der Prozessabläufe) oder zusätzliche Prozesse. Hier werden also hypothetische Informationsverarbeitungsprozesse innerhalb einer bestimmten kognitiven Funktion in einer Weise expliziert, wie man es von Computer Ablaufdiagrammen kennt. In der Anzahl und Vernetzung der Boxen zeigen sich dabei sehr große Unterschiede zwischen den Modellen.
Mathematische Kognitive Modelle: Theory of Visual Attention (TVA)
Es gibt bereits viele kognitive Modelle, welche die in den Boxen und Pfeilen dargestellten kognitiven Prozesse durch mathematische Gleichungen zusätzlich explizieren. Statt einfach nur eine statistische Beziehung zu quantifizieren, wird eine relevante Größe als Funktion einzelner oder einer Reihe anderer empirisch messbarer oder schätzbarer Größen festgelegt.
Die „Theory of Visual Attention“ (TVA), welche im Jahr 1990 von Claus Bundesen entwickelt wurde, stellt ein mithilfe mathematischer Gleichungen formuliertes kognitives Modell der visuellen Aufmerksamkeit dar.
Es handelt sich um eine Generalisierung des 1988 von Hitomi Shibuya und Claus Bundesen entwickelten FIRM-Modells (= two stage fixed-capacity independent race model). Dieses Modell beschreibt den ersten Schritt der Verarbeitung eines Stimulus als Berechnung der Aufmerksamkeitsgewichte (= attentional weights) für jedes Item. Ein solcher Stimulus könnte beispielsweise die Darstellung einer Menge verschiedenfarbiger Items unterschiedlicher Formen und Orientierungen sein. Das Aufmerksamkeitsgewicht ist die Stärke der sensorischen Evidenz, dass es sich dabei um ein Target handelt. Im Anschluss an die Berechnung der Aufmerksamkeitsgewichte wird die vorhandene Verarbeitungskapazität auf die verschiedenen Items in Abhängigkeit ihrer Gewichte geteilt. Auf Items mit hohen Gewichten entfällt somit ein größerer Anteil der Verarbeitungskapazität. Das Ausmaß der Aufmerksamkeit, welches ein Items bekommt, bestimmt, wie schnell es verarbeitet und somit im visuellen Kurzzeitgedächtnis (visual short term memory; VSTM) enkodiert wird. Items mit hoher Aufmerksamkeit haben somit die Chance enkodiert zu werden, bevor der Stimulus verschwindet oder die Kapazitäten des VSTM erreicht sind.
Die TVA beschreibt die Erkennung und Selektion von Objekten/Items im visuelles Feld als Durchführung von perzeptuellen Kategorisierungen. Die Erkennung und Selektion eines Objekts basiert dabei auf dem Wettbewerb zwischen verschiedenen Kategorisierungsmöglichkeiten. Dazu werden zunächst die Gewichte w aller im rezeptiven Feld befindlichen Items x mittels folgender Formel berechnet:
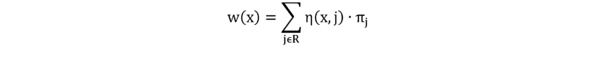
R steht dabei für die Menge aller möglichen Kategorien. Eine visuelle Kategorie j kann beispielsweise eine bestimmte Farbe, Form oder Orientierung sein. Der Term η(x,j) repräsentiert die sensorische Evidenz dafür, dass das Item x zur Kategorie j gehört. Diese sensorische Evidenz kann z.B. durch eine verschwommene Darstellung vermindert oder aber durch Ähnlichkeit zu anderen Items dieser Kategorie erhöht sein. Die Relevanz der Kategorie j für den Beobachter ist πj.
Die Verarbeitungsgeschwindigkeit einer Itemkategorisierung berechnet sich im Anschluss folgendermaßen:
Die Verarbeitungsgeschwindigkeit v(x,j) entspricht der Wahrscheinlichkeit, dass ein Item x als Element der Kategorie j kategorisiert wird. Sie berechnet sich als Produkt der sensorischen Evidenz η(x,j), dass ein Item x zur Kategorie j gehört, dem Bias βj einer Person, Items der Kategorie j zuzuordnen und dem Anteil des Gewichts von Item j am Gesamtgewicht aller Items (Gesamtheit aller Items = S).
Ist die Kategorisierung eines Objekts abgeschlossen, geht dieses bei vorhandenen Gedächtniskapazitäten ins VSTM über. Die Spanne des VSTM ist jedoch begrenzt, weshalb Items, die schneller kategorisiert werden, eine höhere Wahrscheinlichkeit haben ins VSTM zu gelangen. Sind keine Kurzzeitgedächtniskapazitäten mehr vorhanden, kann das betreffende Item nicht bewusst verarbeitet werden.
Aufgrund seiner hohen Komplexität kann dieses Modell der visuellen Aufmerksamkeit auch auf weitere Anwendungskontexte wie zum Beispiel verschiedene Wahrnehmungsaspekte, die auditorische Aufmerksamkeit oder Gedächtnisprozesse übertragen werden. Durch die explizite Formulierung des Modells mittels mathematischer Gleichungen ist es möglich, präzise Vorhersagen über Ergebnisse visueller Aufmerksamkeitsaufgaben zu treffen und das Modell somit zu überprüfen.