Grundlagen Hauptkomponentenanalyse: Unterschied zwischen den Versionen
Elisa (Diskussion | Beiträge) Keine Bearbeitungszusammenfassung |
Keine Bearbeitungszusammenfassung |
||
| (Eine dazwischenliegende Version desselben Benutzers wird nicht angezeigt) | |||
| Zeile 21: | Zeile 21: | ||
[[File:4_1_HKA_1.PNG|650px|Abbildung 1: Darstellung der Hauptkomponenten im unrotierten (links) und rotierten (rechts) Streudiagramm zweier korrelierter Zufallsvariablen]] | [[File:4_1_HKA_1.PNG|650px|link=Ausgelagerte_Bildbeschreibungen#Graphische_Darstellung_der_Hauptkomponentenanalyse|Abbildung 1: Darstellung der Hauptkomponenten im unrotierten (links) und rotierten (rechts) Streudiagramm zweier korrelierter Zufallsvariablen]] | ||
Aktuelle Version vom 10. Mai 2022, 10:51 Uhr
Die Hauptkomponentenanalyse (Principal Component analysis; PCA) ist ein exploratorisches Verfahren zur Datenreduktion, in der möglichst wenige, voneinander unabhängige Hauptkomponenten möglichst viel Varianz in den Variablen erklären sollen. Die PCA verfolgt als faktorenanalytischer Ansatz das Ziel, große Datensätze mit vielen Variablen anhand weniger, nicht beobachtbarer Merkmale (Faktoren) zu beschreiben. Sie geht davon aus, dass sich die Ausprägungen der Probanden in einer Variablen zik als Linearkombination der Faktorwerte fjk darstellen lassen:
![]()
Ein Faktorwert fjk gibt die Ausprägung eines Faktors bei einer Person an. Die Faktorladung aij beschreibt, wie stark ein Faktor über alle Personen hinweg zur Erklärung der Variable beiträgt. Sie entspricht der Korrelation der Hauptkomponente mit der jeweiligen Variablen.
Die Faktoren der PCA erfüllen zwei Bedingungen. Zum einen sind sie orthogonal, also wechselseitig unabhängig zueinander. Die zweite Bedingung ist, dass die Faktoren sukzessive maximale Varianz aufklären. Die erste Hauptkomponente wird demnach so festgelegt, dass sie maximale Varianz in den Daten erklärt. Die zweite Hauptkomponente klärt dann, unabhängig zur ersten Komponente, den maximalen Anteil der verbliebenen Varianz in den Daten auf. Nach diesem Schema werden so viele Komponenten bestimmt, wie es Variablen gibt, wobei jede Komponente weniger Varianz aufklärt, als alle zuvor bestimmten Komponenten.
Die Festlegung darauf, welche Faktoren zur Beschreibung der Daten verwendet werden sollen, beruht auf der Analyse der Eigenwerte (λ) der Faktoren. Ein Eigenwert beschreibt, welchen Anteil der Gesamtvarianz aller Variablen ein Faktor aufklärt und entspricht der Summe der quadrierten Faktorladungen aller Variablen auf diesen Faktor. Die Anzahl an Faktoren kann mit verschiedenen Methoden bestimmt werden und ist auch von inhaltlichen Überlegungen abhängig.
Die Kommunalität (h²) gibt an, welcher Anteil der Varianz einer Variablen durch alle Faktoren aufgeklärt wird. Sie ergibt sich aus der Summe der quadrierten Faktorladungen einer Variablen auf allen Faktoren. Wenn alle Hauptkomponenten zur Erklärung der Variablen verwendet werden, wird jede Variable vollständig durch das Modell erklärt. Die Kommunalität aller Variablen entspricht in diesem Fall 1.
Beispiel
In einer fiktiven Beispielstudie wird eine Hauptkomponentenanalyse für einen Datensatz mit 2 Variablen, die mit r = 0.8 korrelieren, berechnet. Das Ziel der Hauptkomponentenanalyse ist hier, die Varianz der beiden Variablen durch zwei voneinander unabhängige Faktoren zu beschreiben, wobei die erste Hauptkomponente maximale mögliche Varianz der Variablen aufklären soll. Dafür wird im ersten Schritt eine Hauptkomponente bestimmt, die den maximalen Anteil der Gesamtvarianz der Variablen erklärt. In Abbildung 1 entspricht die Hauptkomponente der Geraden, die durch die Punktwolke verläuft. Die zweite Hauptkomponente wird orthogonal zur ersten Hauptkomponente angelegt und erklärt den verbliebenen Anteil der Varianz in den Daten. Durch die Orthogonalität der beiden Faktoren entsteht nach einer Rotation ein neues Koordinatensystem mit den Hauptkomponenten als x- und y-Achse (Abbildung 1, rechts).
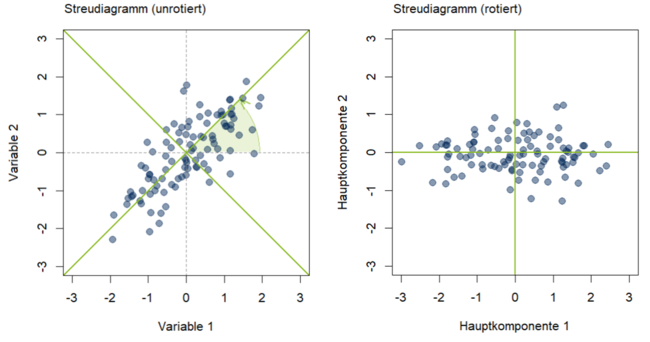
Auf dem rotierten Koordinatensystem ist es möglich zu erkennen, welchen Wert ein Datenpunkt auf den Hauptkomponenten besitzt. Hier wird außerdem nochmal deutlich, dass die erste Hauptkomponente einen Großteil der Varianzaufklärung übernimmt. Die Ergebnisse der Hauptkomponentenanalyse sind in Abbildung 2 dargestellt.
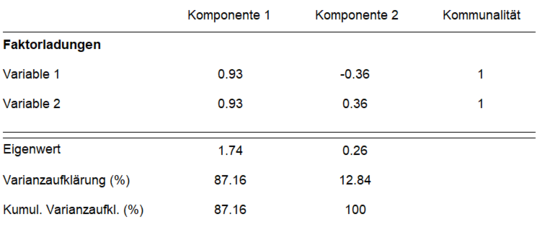
Die Faktorladungen, also die Korrelationen der Hauptkomponenten mit den Variablen, betragen 0.93 bzw. 0.36/-0.36. Da genauso viele Faktoren wie Hauptkomponenten verwendet wurden, betragen die Kommunalitäten der beiden Variablen entsprechend ihrer Gesamtvarianz h² = 1. Die Eigenwerte der beiden Komponenten zeigen, dass ein Großteil der Varianz durch die erste Hauptkomponente erklärt wird (λ1 = 1.76). Normiert an der Gesamtvarianz des Modells (2) ergibt sich für die erste Komponente eine Varianzaufklärung von 87.16 %. Die restlichen 12.84 % werden entsprechend durch die zweite Komponente aufgeklärt. Aufgrund des geringen Eigenwertes und der geringen Varianzaufklärung der zweiten Komponente könnte diese im Zuge der Datenreduktion entfernt werden. Die Faktorladungen und Eigenwerte des ersten Faktors würden dabei identisch bleiben. Lediglich die Kommunalitäten der beiden Variablen würden geringer werden.
![]() kkk Im Video wird das Prinzip der Hauptkomponentenanalyse in näher erläutert.
kkk Im Video wird das Prinzip der Hauptkomponentenanalyse in näher erläutert.
![]() kkk In der interaktiven Simulation lassen sich verschiedene Hauptkomponentenanalysen zweier Variablen mit unterschiedlichen Korrelationen grafisch nachvollziehen.
kkk In der interaktiven Simulation lassen sich verschiedene Hauptkomponentenanalysen zweier Variablen mit unterschiedlichen Korrelationen grafisch nachvollziehen.
Weiterführende Literatur
Bortz, J., & Schuster, C. (2016). Statistik für Human- und Sozialwissenschaftler. Berlin: Springer.
Bühner, M. (2010). Einführung in die Test- und Fragebogenkonstruktion (3. Aufl.; Kapitel 6). München: Pearson Studium.
Eid, M., Gollwitzer, M., & Schmitt, M. (2017). Statistik und Forschungsmethoden. Weinheim: Beltz.