Stichprobenauswahl: Unterschied zwischen den Versionen
Keine Bearbeitungszusammenfassung |
Elisa (Diskussion | Beiträge) Keine Bearbeitungszusammenfassung |
||
| (3 dazwischenliegende Versionen von einem anderen Benutzer werden nicht angezeigt) | |||
| Zeile 1: | Zeile 1: | ||
{{Nav|Navigation| | {{Nav|Navigation|Stichproben|Stichproben}} | ||
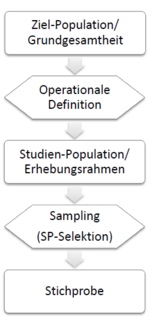
Untersuchungen beschreiben [[Populationen]] anhand von Populationsparametern (wie | Untersuchungen beschreiben [[Populationen]] anhand von Populationsparametern (wie Mittelwert und [https://de.wikipedia.org/wiki/Streuung_%28Statistik%29 Streuwert]). Da meist nicht die ganze Population untersucht werden kann, muss eine Stichprobe(ein Sample) ausgewählt werden, die möglichst repräsentativ für ihre Population sein sollte. <br/> <br/> | ||
Die Stichprobenselektion kann jedoch zu Verzerrungen ('''Stichprobenfehler''') führen. Diese können durch eine nicht-repräsentatives '''Sampling''' und damit einer verzerrten Stichprobe zustande kommen, oder schon auf der Ebene der operationalen Definition und damit eines invaliden Erhebungsrahmens beginnen: <br/> | Die Stichprobenselektion kann jedoch zu Verzerrungen ('''Stichprobenfehler''') führen. Diese können durch eine nicht-repräsentatives '''Sampling''' und damit einer verzerrten Stichprobe zustande kommen, oder schon auf der Ebene der operationalen Definition und damit eines invaliden Erhebungsrahmens beginnen: <br/> | ||
Auf der Ebene der operationalen Definition liegt eine '''Falschzuordnung''' vor, wenn durch die Operationalisierung und eventuell damit verbundene Messung zu viele (Überfassung) oder zu wenige (Unterfassung) Individuen erfasst werden, sodass die Studienpopulation nicht der Zielpopulation entspricht: Es muss also wie üblich die Validität der Operationalisierung und Reliabilität der Messung berücksichtigt werden, da diese zu Verzerrungen führen können. Eine Beispiel für die Falschzuordnung durch eine unreliable Messung wäre, wenn in einer Studie „Depressive Menschen“ die Ziel-Population darstellen und diese Gruppe operational als „Menschen mit der Diagnose schwerer depressiver Symptome“ definiert wird: da jedes Diagnoseinstrument eine begrenzte Reliabilität aufweist, werden manche eigentlich „schwer depressive“ Menschen nicht erfasst werden (Unterfassung) und manche eigentlich „mittelschwer depressive“ Menschen als zur Population gehörig erfasst werden (Überfassung). Ein Beispiel für eine Operationalisierungsproblem liegt vor, wenn z.B. „gebährfähige Frauen“ die Population des Interesses darstellen: eine umsetzbare Operationalisierung könnte z.B. sein „Frauen zwischen 14- 40 Jahren“. Nun können aber Frauen unter 14 oder über 40 durchaus noch gebährfähig sein, und es kann auch Frauen geben, die zwischen 14 und 40 Jahren alt sind, aber nicht/nicht mehr gebährfähig sind. Die pragmatische Operationalisierung selbst führt hier zu einer möglichen Unter-/ bzw. Überfassung. <br/> <br/> | Auf der Ebene der operationalen Definition liegt eine '''Falschzuordnung''' vor, wenn durch die Operationalisierung und eventuell damit verbundene Messung zu viele (Überfassung) oder zu wenige (Unterfassung) Individuen erfasst werden, sodass die Studienpopulation nicht der Zielpopulation entspricht: Es muss also wie üblich die Validität der Operationalisierung und Reliabilität der Messung berücksichtigt werden, da diese zu Verzerrungen führen können. Eine Beispiel für die Falschzuordnung durch eine unreliable Messung wäre, wenn in einer Studie „Depressive Menschen“ die Ziel-Population darstellen und diese Gruppe operational als „Menschen mit der Diagnose schwerer depressiver Symptome“ definiert wird: da jedes Diagnoseinstrument eine begrenzte Reliabilität aufweist, werden manche eigentlich „schwer depressive“ Menschen nicht erfasst werden (Unterfassung) und manche eigentlich „mittelschwer depressive“ Menschen als zur Population gehörig erfasst werden (Überfassung). Ein Beispiel für eine Operationalisierungsproblem liegt vor, wenn z.B. „gebährfähige Frauen“ die Population des Interesses darstellen: eine umsetzbare Operationalisierung könnte z.B. sein „Frauen zwischen 14- 40 Jahren“. Nun können aber Frauen unter 14 oder über 40 durchaus noch gebährfähig sein, und es kann auch Frauen geben, die zwischen 14 und 40 Jahren alt sind, aber nicht/nicht mehr gebährfähig sind. Die pragmatische Operationalisierung selbst führt hier zu einer möglichen Unter-/ bzw. Überfassung. <br/> <br/> | ||
| Zeile 6: | Zeile 6: | ||
Auf der Ebene der Stichprobenselektion kann eine nicht-repräsentative Stichprobe zu Verzerrungen führen. Anhand des Auswahlprozederes lassen sich Stichproben dementsprechend in [[probabilistische Stichproben|probabilistische]] und [[nicht-probabilistische Stichproben|nicht-probablistische]] unterteilen. <br/> <br/> | Auf der Ebene der Stichprobenselektion kann eine nicht-repräsentative Stichprobe zu Verzerrungen führen. Anhand des Auswahlprozederes lassen sich Stichproben dementsprechend in [[probabilistische Stichproben|probabilistische]] und [[nicht-probabilistische Stichproben|nicht-probablistische]] unterteilen. <br/> <br/> | ||
[[Datei:SP-Auswahl.png|150px|zentriert]] | [[Datei:SP-Auswahl.png|150px|zentriert|link=Ausgelagerte_Bildbeschreibungen#Stichprobenauswahl|Ausgelagerte Bildbeschreibung von Stichprobenauswahl]] | ||
Aktuelle Version vom 13. Dezember 2021, 22:40 Uhr
Untersuchungen beschreiben Populationen anhand von Populationsparametern (wie Mittelwert und Streuwert). Da meist nicht die ganze Population untersucht werden kann, muss eine Stichprobe(ein Sample) ausgewählt werden, die möglichst repräsentativ für ihre Population sein sollte.
Die Stichprobenselektion kann jedoch zu Verzerrungen (Stichprobenfehler) führen. Diese können durch eine nicht-repräsentatives Sampling und damit einer verzerrten Stichprobe zustande kommen, oder schon auf der Ebene der operationalen Definition und damit eines invaliden Erhebungsrahmens beginnen:
Auf der Ebene der operationalen Definition liegt eine Falschzuordnung vor, wenn durch die Operationalisierung und eventuell damit verbundene Messung zu viele (Überfassung) oder zu wenige (Unterfassung) Individuen erfasst werden, sodass die Studienpopulation nicht der Zielpopulation entspricht: Es muss also wie üblich die Validität der Operationalisierung und Reliabilität der Messung berücksichtigt werden, da diese zu Verzerrungen führen können. Eine Beispiel für die Falschzuordnung durch eine unreliable Messung wäre, wenn in einer Studie „Depressive Menschen“ die Ziel-Population darstellen und diese Gruppe operational als „Menschen mit der Diagnose schwerer depressiver Symptome“ definiert wird: da jedes Diagnoseinstrument eine begrenzte Reliabilität aufweist, werden manche eigentlich „schwer depressive“ Menschen nicht erfasst werden (Unterfassung) und manche eigentlich „mittelschwer depressive“ Menschen als zur Population gehörig erfasst werden (Überfassung). Ein Beispiel für eine Operationalisierungsproblem liegt vor, wenn z.B. „gebährfähige Frauen“ die Population des Interesses darstellen: eine umsetzbare Operationalisierung könnte z.B. sein „Frauen zwischen 14- 40 Jahren“. Nun können aber Frauen unter 14 oder über 40 durchaus noch gebährfähig sein, und es kann auch Frauen geben, die zwischen 14 und 40 Jahren alt sind, aber nicht/nicht mehr gebährfähig sind. Die pragmatische Operationalisierung selbst führt hier zu einer möglichen Unter-/ bzw. Überfassung.
Auf der Ebene der Stichprobenselektion kann eine nicht-repräsentative Stichprobe zu Verzerrungen führen. Anhand des Auswahlprozederes lassen sich Stichproben dementsprechend in probabilistische und nicht-probablistische unterteilen.